
Cerebras IPO (S-1 Deep Dive)
20x oversubscribed... and an NVIDIA killer?

Hey everyone!
Today, we’re looking at something slightly different. For the first time, I’ll be covering the S-1 (registration statement) of a business looking to IPO imminently.
The business we’ll dive into today is Cerebras ($CBRS). Cerebras is at its core, an AI chip and AI compute infrastructure company. And we know how high in demand these are today.
It will IPO on Thursday this week (14th May 2026) with Reuters reporting an exclusive earlier this week that it intends to raise its IPO price range to $150-$160 ($34B market cap) up from $115-$125 ($26.6B market cap). It also intends to increase its offering to 30M shares, up from 28M shares, meaning it will raise about $4.8B at the top end.
Against $510M in 2025 revenue, that implies a ~67x P/S, a steep number for sure.
But of course, that is a simplified manner of looking at things. In this piece, we will look at the growth prospects of Cerebras, determine if the business has a moat, and just how large it could become. Is this truly an NVIDIA competitor, or merely a pretender?
Table of Contents
Introduction
Company History
Business Model
Value Proposition
Product Offerings
Moats & Differentiation
Market Context & Industry Positioning
Competitive Landscape
Financials
Ownership & Management
Valuation
Catalysts & Outlook
Bull and Bear Case
Concluding Thoughts (What I am personally doing)
1. Introduction
If you walk into any AI data center today, you will find racks full of NVIDIA GPUs. Each GPU is a small chip, about the size of a postage stamp. To train or run big AI models, you wire thousands of these little chips together with cables, switches, and networking gear. The model gets "chopped up" and spread across all of them.
This works, and is why NVIDIA is the largest company in the world. However, there is one problem, moving data between chips is slow and power-hungry. Every time one GPU needs to talk to another, the signal has to leave the chip, travel down a wire, through a switch, and into the next chip. AI models do this trillions of times. The chips end up spending most of their energy and time just shuffling data around, not actually computing.
Cerebras solves this exact problem. Instead of cutting a silicon wafer into hundreds of small chips, Cerebras decided to use the entire wafer as one chip.
The result is the Wafer-Scale Engine (WSE), the largest computer chip ever sold commercially, about the size of a dinner plate.

To give you a sense of scale, the current WSE-3 is:
58 times larger than NVIDIA’s flagship B200 chip
Has 900,000 compute cores on one piece of silicon (a B200 has tens of thousands)
Has 44 GB of memory built directly onto the chip (250x more than a B200)
Moves data internally at 21 petabytes per second (about 2,600 times the memory bandwidth of a B200)

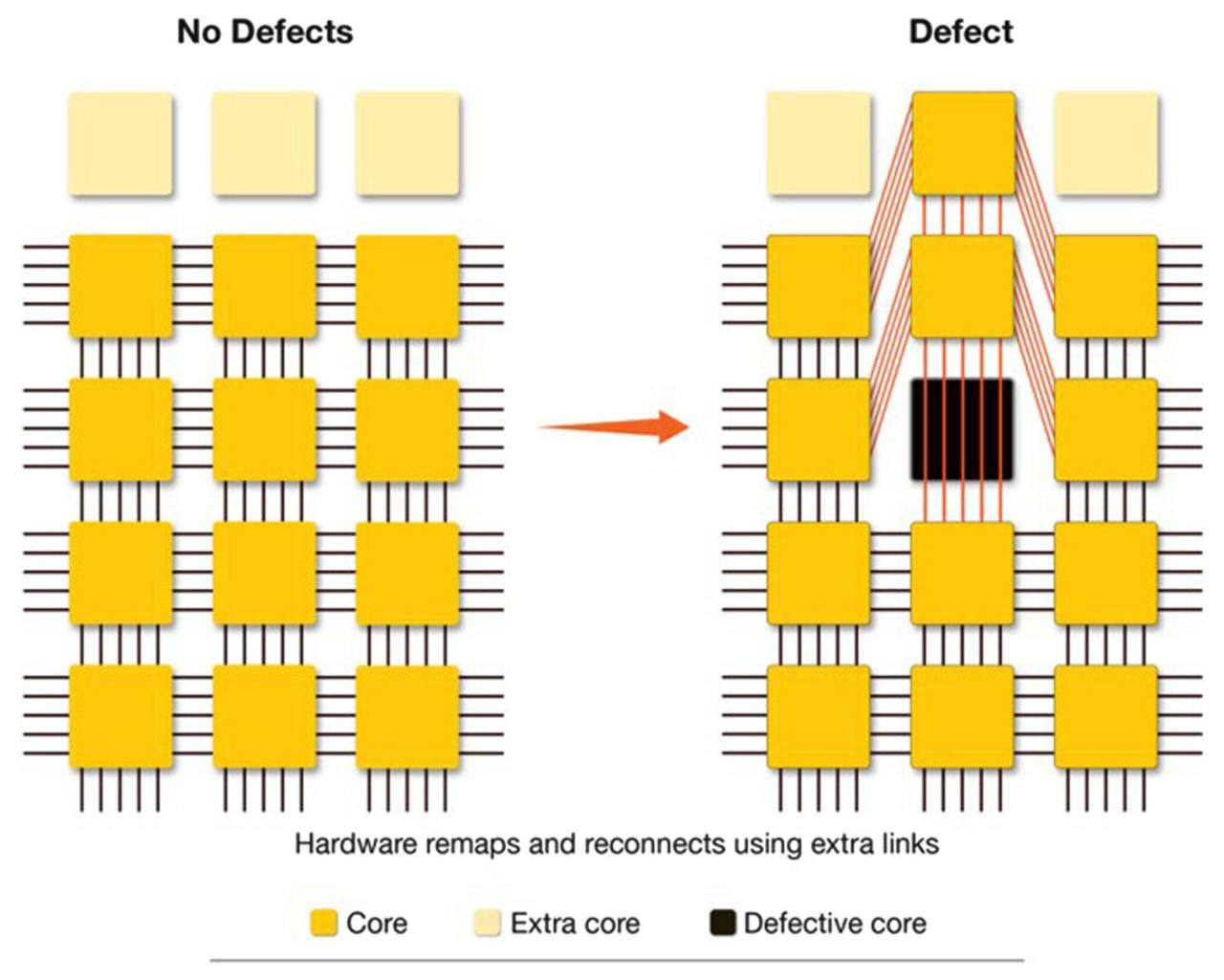
For 50+ years, the entire chip industry assumed wafer-scale chips couldn't be made commercially. For 3 reasons:
Yield. Every silicon wafer has tiny manufacturing defects. The bigger the chip, the more likely it contains a defect, and traditionally one defect ruins the whole chip. A wafer-sized chip should be un-manufacturable.
Power and Heat. A chip the size of a dinner plate draws enormous power and generates enormous heat. Cooling it without melting the system around it is hard.
Connecting the regions. Wafers are normally exposed to light in small rectangular sections called "reticles." Getting those sections to communicate as one chip required inventing a new manufacturing technique.
Cerebras spent roughly a decade solving all three. Their architecture is fault-tolerant. If a small region of the chip has a defect, the chip routes around it. They invented a custom water-cooling system and a proprietary cross-reticle interconnect built into TSMC's fabrication process.
When Cerebras first shipped chips in 2020, the market didn't really need them as AI was nascent, training was slow, and most people didn't care about speed.
The ChatGPT moment happened, and then “reasoning models” were released with o1 by OpenAI. Modern AI models think through questions, sometimes generating tens of thousands of internal tokens before responding. Speed became a bottleneck, and a coding agent that takes 30 seconds to respond is useless compared to one that responds in 2 seconds.
In January 2026, OpenAI signed a $20+ billion deal to run a chunk of its inference compute on Cerebras hardware. And in March 2026, AWS agreed to put Cerebras chips inside Amazon Bedrock, making Cerebras compute available to every AWS developer.
2. Company History
Cerebras was founded in 2015, 11 years ago by 5 founders: Andrew Feldman (CEO), Gary Lauterbach, Michael James, Sean Lie and Jean-Philippe Fricker. The 5 of them worked together at SeaMicro (a low-power server startup), started in 2007 by Andrew and Gary and was later sold to AMD in 2012 for $334M.
That exit gave the founding team operational credibility and the AMD network that would later prove instrumental.
The founders saw in 2015 that AI was on the horizon and knew it would consume vast amounts of compute. They made two fundamental bets.
First, existing general-purpose processors would not be sufficient for AI. They believed what PCs did for x86, graphics did for GPUs and mobile did for ARM, would prove true in AI too.
Second, they bet that modifying existing compute architectures would not realise AI’s potential. They would need to build a new computer architecture from first principles, optimised in every way for AI.
Both bets were contrarian at the time, and have proved to be right.
Timeline Highlights:
2016: Series A of $27M led by Benchmark, Foundation Capital, and Eclipse Ventures
2018: Elon Musk reportedly tried to acquire Cerebras through Tesla to support OpenAI — founders declined
August 2019: First-generation WSE-1 announced (16nm, 400,000 cores)
2020: First CS-1 systems delivered to Argonne, NETL, GSK etc…
April 2021: WSE-2/CS-2 launched at 7nm (850,000 cores, 40GB SRAM)
November 2021: Series F at >$4B valuation, led by Alpha Wave Global with G42 participation.
2023: Condor Galaxy supercomputer network announced in partnership with G42
2024: WSE-3/CS-3 launched at 5nm. First S-1 filed in September. CFIUS opens review of G42’s stake within weeks; IPO indefinitely delayed
May 2025: CEO Feldman publicly confirms CFIUS clearance obtained
September 2025: Series G of $1.1B at $8.1B valuation
October 2025: Original S-1 withdrawn (”out of date”)
December 2025: $1B OpenAI loan + warrants secured. NVIDIA acquires Groq IP for ~$20B in the same month (Groq is the closest pure-play competitor to Cerebras)
January 2026: Master Relationship Agreement with OpenAI announced — $20B+ over multi years, 750 MW base
February 2026: Series H of $1B at $23B valuation, led by Tiger Global, with AMD, Coatue, Benchmark, and Fidelity participating
March 2026: Binding term sheet signed with AWS for Bedrock integration
April 17, 2026: New S-1 filed
3. Business Model
The best way to describe Cerebras is as a vertically integrated AI compute company. They have three revenue streams that are converging:
Hardware Sales (On-Prem Systems)
Customers buy CS-3 systems (a third-generation, wafer-scale AI accelerator system designed for training and inferencing massive AI models) from Cerebras outright. This was historically the entire business. In 2025, this accounted for 70% ($358.4M) of total revenues.
Customers in this bucket include Sovereign AI initiatives, foundation model labs that demand data isolation, and national labs/defence.
Cloud (Cerebras Cloud + Partner Clouds)
Customers consume tokens or rent compute by the month/year through Cerebras's own cloud, or through AWS, Microsoft Azure Marketplace, IBM watsonx, Vercel, OpenRouter, and Hugging Face. In 2025, this accounted for 30% ($151.6M) of total revenues.
The OpenAI Master Relationship Agreement is structured primarily as a multi-year compute commitment funnelled through this layer.
Co-development & AI-model Services
Cerebras's engineers help customers select architectures, prepare training data, build draft/speculative-decoding models, and tune deployments. Bundled with strategic accounts (explicitly cited in the S-1 as a reason top-10 customers grew spend ~80% within 12 months of initial purchase.)
This is not a revenue generating segment, but is inarguably a key piece of Cerebras’ competitive advantage.
Revenue Concentration
The S-1 discloses MBZUAI (world’s first graduate-level, research-based artificial intelligence university in UAE) at 62% of 2025 revenue and G42 (leading UAE-based AI and cloud computing company) at 24%. Together, they account for 86% of total revenues. However, OpenAI’s $20B+ commitment will reshape this mix dramatically from 2026 onward.
4. Value Proposition
The key to Cerebras’ pitch is all about speed.
In Cerebras’ S-1, they make the analogy that going from GPU inference to Cerebras inference is “like going from dial-up to broadband”.

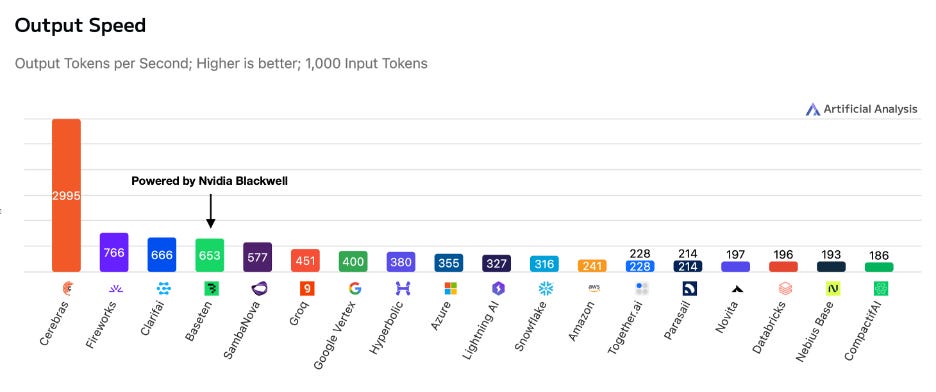
Cerebras claims that they are up to 15x faster than leading GPU solutions on standard open-source benchmarks. They are 1,000x+ faster on certain exotic workloads and are >10x faster in training time-to-solution vs. same-generation GPUs.
This speed also unlocks several other advantages for Cerebras:
Speed unlocks new product categories. For instance real-time coding agents (Cursor, Codex, Claude Code), digital twins/voice avatars that require sub-second latency, and “deep research” agents that can scan thousands of documents in seconds.
Quality. GPU-based systems force a tradeoff between answer quality and latency (developers cap reasoning tokens to keep response times tolerable). Cerebras’ speed allows models to use more reasoning tokens within the same response time, producing better answers for users.
Cost. Power is the dominant operating expense in AI compute, and most of that power is spent moving data between chips. Keeping data on a single wafer reduces data movement and the elaborate networking stack that comes with GPU clusters.
In essence, Cerebras is betting that wafer-scale is what wins AI, much like how x86 won PCs and ARM won mobile.
5. Product Offerings
Hardware
Wafer-Scale Engine 3 (WSE-3)

This is the main product. WSE-3 uses a 5nm TSMC node with 900,000 AI cores, 44GB on-chip SRAM, 21 PB/s memory bandwidth, 4 trillion transistors, 46,225 mm² die.
It is 58x larger than NVIDIA’s B200, with 19x more transistors, 250x more on-chip memory, and 2,625x more memory bandwidth than a B200 package.

CS-3 System

This is the data-center-ready chassis which houses one WSE-3 with proprietary power delivery, water cooling, networking and slots into standard racks.
Cerebras AI Supercomputers

Clusters of CS-3 systems orchestrated as a single logical machine. The Condor Galaxy network with G42 represents some of the largest deployed.


Software
CSoft (Cerebras Compiler)
Compiles PyTorch models directly to the WSE. No CUDA dependency.
Inference Serving Stack
Manages hosting, scaling, and routing; exposes standard OpenAI-compatible API endpoints.
Cluster Manager
Telemetry, scheduling, health monitoring. Lets customers flip between training and inference on the same systems.
Deployment Models
On-premises
Full CS-3 supercomputers shipped to customer data centers (Sovereign AI, defense, regulated enterprises, foundation model labs).
Cerebras Cloud
Managed inference and training, API-based.
Partner Clouds
AWS Bedrock, Microsoft Azure Marketplace, IBM watsonx, Vercel, OpenRouter, Hugging Face.
Hybrid
Unified software stack across on-prem and cloud.
Roadmap
Cerebras has shipped 3 generations of WSE, from 16nm to 7nm and now 5nm. The company intends to continue investing in expanding on-chip memory, memory bandwidth, interconnect density, and process-node migration.
Notably, the architecture is presented as forwards-compatible, meaning customers don't have to rewrite code as Cerebras moves between generations. Currently, when NVIDIA releases a new GPU generation (say H100 to B200), developers often have to re-write or re-optimise their code to take full advantage of the new hardware. The CUDA ecosystem mitigates this but doesn't eliminate it.
Cerebras claims that customers won’t have to do this, as a model that ran on WSE-2 will run on WSE-3 without code changes and will run on WSE-4 the same way.
6. Moats & Differentiation
I believe Cerebras’ moats are purely technological. That could turn into distributional or other types of moats in future, but I do view it to be rather limited at this point.
Wafer-Scale Integration IP and Process Know-How
Historically, there have always been two problems that made wafer-scale chips impossible to produce commercially.
Firstly, chip-making machines can only “print” patterns onto silicon in small rectangular sections (about the size of a postage stamp). Normally, those sections get cut apart into individual chips. To make one giant chip, Cerebras needed wires that cross between those sections. They worked with TSMC for years to develop a custom process that creates these connections. This is now baked into TSMC’s manufacturing flow specifically for Cerebras.
Secondly, defects. Every silicon wafer has tiny manufacturing flaws scattered randomly across it. A normal chip with one flaw gets thrown out. Each Cerebras chip, owing to its size, has 40-50 flaws. By normal logic, it should be unusable. However, Cerebras solved this by designing the chip with hundreds of thousands of small identical cores plus spare cores. When a defect is found, the chip automatically routes around it and switches in a spare.
Multiple companies have tried wafer-scale chips for 50 years but only Cerebras has commercialised one. Replicating this will require years of work with TSMC.
Full-Stack Co-Design
Running AI on NVIDIA GPUs is complicated as customers manage a stack of software from CUDA to distributed training frameworks, cluster management and inference servers. Major AI labs have to hire hundreds of engineers just to keep the stack working.
Cerebras’ pitch is that you are able to write your model in PyTorch, hand it to Cerebras’ compiler, and it runs smoothly with all the complexity hidden. Once a customer is committed, this becomes a workflow lock-in, similar to a switching cost moat that the likes of Microsoft possesses with its Microsoft Suite.
Manufacturing Relationship
Cerebras has spent years working with TSMC on the cross-reticle process. Even a well-funded competitor would need 3-5 years to catch up. However, this also means TSMC is a single point of failure. If something disrupts TSMC, Cerebras has no Plan B.
Strategic Partnerships
Cerebras has three anchor relationships today, which is probably why most are interested in the stock, and also proves its capability.
Firstly, it has a $20B+ multi-year deal with OpenAI, and a $1B loan plus warrants for ~10% of Cerebras stock if the full deal is exercised. OpenAI has a direct financial incentive in Cerebras’ success.
Secondly, Cerebras chips are being added to Amazon Bedrock, which means every AWS developer will be able to use them. This is a level of distribution that Cerebras could never build itself, but provides them with network effects.
Lastly, the legacy relationship in MBZUAI and G42 that today account for 86% of their revenue. Their close relationship has enabled the business to put up the strong numbers and validated their investment in wafer-scale chips.
While these may not be moats in the strict sense, they create demand visibility, customer validation, and a sales proof point.
7. Market Context & Industry Positioning
Bloomberg Intelligence estimates that the combined AI training infrastructure and inference market was $251B in 2025 and will grow to $672B by 2029 implying a 28% CAGR. Inference is also growing >2x faster than training infrastructure.
IDC projects AI investments will yield $22.3T in global GDP impact by 2030.
I don’t think any of us are doubting these numbers. They are quite clearly a large enough addressable market and even a small slice probably supports a $34B market cap. The question is, how large of a slice could Cerebras get and how many other players are vying for that slice?
The Inference Shift
One of the dominant stories in the past 6 months has been that inference, not training, drives the bulk of new compute demand. This has been corroborated by the performance of AMD compared to NVDA in the past year (+320% v +80%). The perception has always been that AMD is more focused on inference than NVDA.
The demand for inference is driven by 3 compounding forces:
More users
Higher frequency of use per user
More compute per use (reasoning models do “test-time compute” generating long internal chains of thought that consume many more tokens than a single Q&A)
Inference-time compute is driving the demand for Cerebras. Due to reasoning models, speed has become a binding constraint rather than a nice-to-have. A 15x speed advantage on a 30-second-thinking reasoning model is more economically meaningful than a 15x speed advantage on a 1-second chat reply.
HBM Bottleneck
A point worth flagging is that Cerebras is a natural hedge against HBM (High Bandwidth Memory) shortages. GPUs depend on HBM, which is supply-constrained by Samsung/SK Hynix/Micron capacity. Cerebras uses on-chip SRAM. As HBM remains tight through 2026-2027, this is a structural tailwind for Cerebras.
8. Competitive Landscape
This is the most important section to understand, because Cerebras's valuation depends almost entirely on whether they can hold a defensible position against this list.
18 months ago, the AI silicon market was a wild zoo with dozens of well-funded competitors (Cerebras, Groq, SambaNova, Graphcore, Tenstorrent, Mythic, Rain AI, Tachyum, Lightmatter, D-Matrix etc.), most of whom claimed to be the “NVIDIA killer”. The inference compute market has consolidated dramatically in the last six months.